Comparing PostgreSQL and ClickHouse
Postgres vs ClickHouse: Equivalent and different concepts
Users coming from OLTP systems who are used to ACID transactions should be aware that ClickHouse makes deliberate compromises in not fully providing these in exchange for performance. ClickHouse semantics can deliver high durability guarantees and high write throughput if well understood. We highlight some key concepts below that users should be familiar with prior to working with ClickHouse from Postgres.
Shards vs Replicas
Sharding and replication are two strategies used for scaling beyond one Postgres instance when storage and/or compute become a bottleneck to performance. Sharding in Postgres involves splitting a large database into smaller, more manageable pieces across multiple nodes. However, Postgres does not support sharding natively. Instead, sharding can be achieved using extensions such as Citus, in which Postgres becomes a distributed database capable of scaling horizontally. This approach allows Postgres to handle higher transaction rates and larger datasets by spreading the load across several machines. Shards can be row or schema-based in order to provide flexibility for workload types, such as transactional or analytical. Sharding can introduce significant complexity in terms of data management and query execution as it requires coordination across multiple machines and consistency guarantees.
Unlike shards, replicas are additional Postgres instances that contain all or some of the data from the primary node. Replicas are used for various reasons, including enhanced read performance and HA (High Availability) scenarios. Physical replication is a native feature of Postgres that involves copying the entire database or significant portions to another server, including all databases, tables, and indexes. This involves streaming WAL segments from the primary node to replicas over TCP/IP. In contrast, logical replication is a higher level of abstraction that streams changes based on INSERT, UPDATE, and DELETE operations. Although the same outcomes may apply to physical replication, greater flexibility is enabled for targeting specific tables and operations, as well as data transformations and supporting different Postgres versions.
In contrast, ClickHouse shards and replicas are two key concepts related to data distribution and redundancy. ClickHouse replicas can be thought of as analogous to Postgres replicas, although replication is eventually consistent with no notion of a primary. Sharding, unlike Postgres, is supported natively.
A shard is a portion of your table data. You always have at least one shard. Sharding data across multiple servers can be used to divide the load if you exceed the capacity of a single server with all shards used to run a query in parallel. Users can manually create shards for a table on different servers and insert data directly into them. Alternatively, a distributed table can be used with a sharding key defining to which shard data is routed. The sharding key can be random or as an output of a hash function. Importantly, a shard can consist of multiple replicas.
A replica is a copy of your data. ClickHouse always has at least one copy of your data, and so the minimum number of replicas is one. Adding a second replica of your data provides fault tolerance and potentially additional compute for processing more queries (Parallel Replicas can also be used to distribute the compute for a single query thus lowering latency). Replicas are achieved with the ReplicatedMergeTree table engine, which enables ClickHouse to keep multiple copies of data in sync across different servers. Replication is physical: only compressed parts are transferred between nodes, not queries.
In summary, a replica is a copy of data that provides redundancy and reliability (and potentially distributed processing), while a shard is a subset of data that allows for distributed processing and load balancing.
ClickHouse Cloud uses a single copy of data backed in S3 with multiple compute replicas. The data is available to each replica node, each of which has a local SSD cache. This relies on metadata replication only through ClickHouse Keeper.
Eventual consistency
ClickHouse uses ClickHouse Keeper (C++ ZooKeeper implementation, ZooKeeper can also be used) for managing its internal replication mechanism, focusing primarily on metadata storage and ensuring eventual consistency. Keeper is used to assign unique sequential numbers for each insert within a distributed environment. This is crucial for maintaining order and consistency across operations. This framework also handles background operations such as merges and mutations, ensuring that the work for these is distributed while guaranteeing they are executed in the same order across all replicas. In addition to metadata, Keeper functions as a comprehensive control center for replication, including tracking checksums for stored data parts, and acts as a distributed notification system among replicas.
The replication process in ClickHouse (1) starts when data is inserted into any replica. This data, in its raw insert form, is (2) written to disk along with its checksums. Once written, the replica (3) attempts to register this new data part in Keeper by allocating a unique block number and logging the new part's details. Other replicas, upon (4) detecting new entries in the replication log, (5) download the corresponding data part via an internal HTTP protocol, verifying it against the checksums listed in ZooKeeper. This method ensures that all replicas eventually hold consistent and up-to-date data despite varying processing speeds or potential delays. Moreover, the system is capable of handling multiple operations concurrently, optimizing data management processes, and allowing for system scalability and robustness against hardware discrepancies.
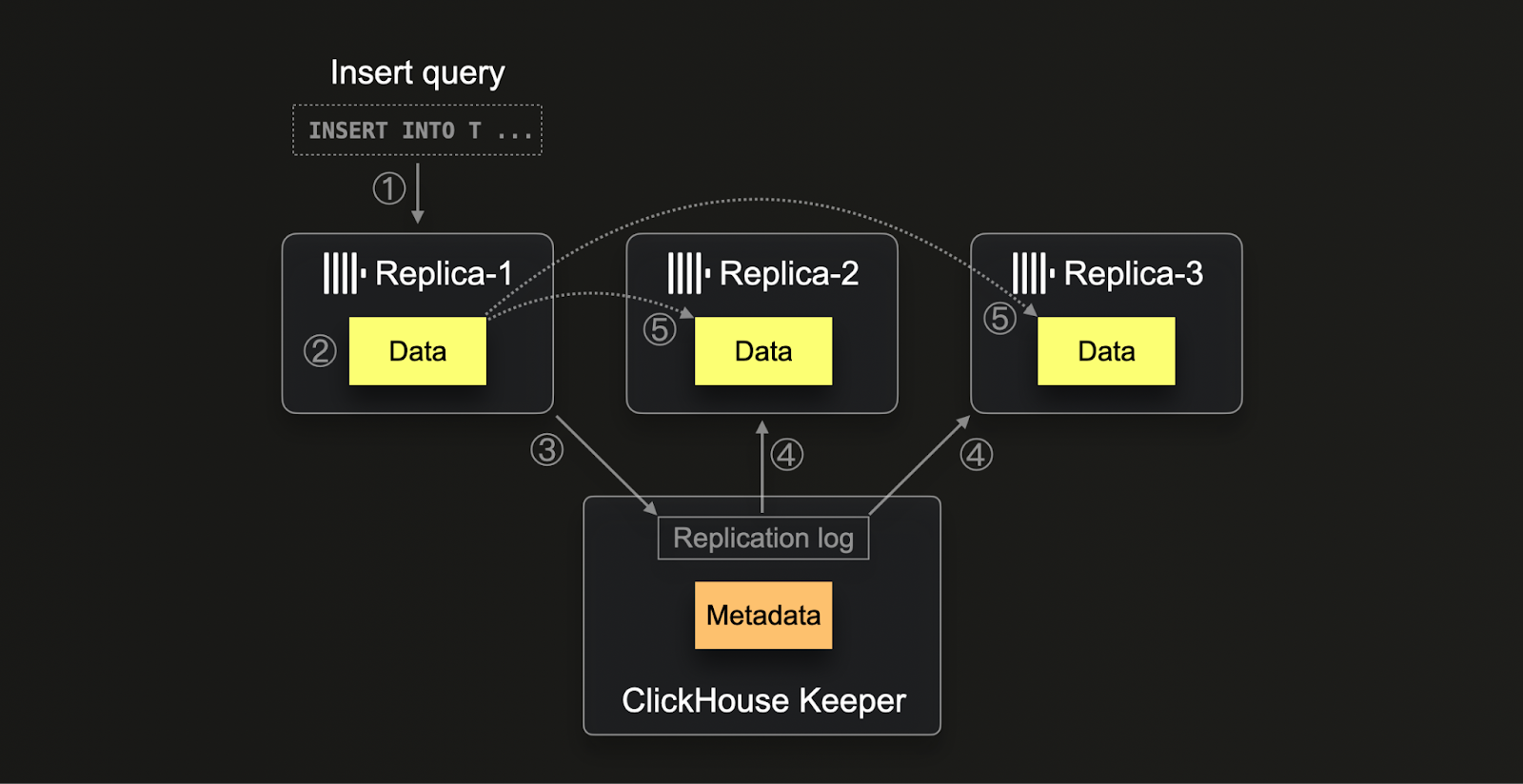
Note that ClickHouse Cloud uses a cloud-optimized replication mechanism adapted to its separation of storage and compute architecture. By storing data in shared object storage, data is automatically available for all compute nodes without the need to physically replicate data between nodes. Instead, Keeper is used to only share metadata (which data exists where in object storage) between compute nodes.
PostgreSQL employs a different replication strategy compared to ClickHouse, primarily using streaming replication, which involves a primary replica model where data is continuously streamed from the primary to one or more replica nodes. This type of replication ensures near real-time consistency and is synchronous or asynchronous, giving administrators control over the balance between availability and consistency. Unlike ClickHouse, PostgreSQL relies on a WAL (Write-Ahead Logging) with logical replication and decoding to stream data objects and changes between nodes. This approach in PostgreSQL is more straightforward but might not offer the same level of scalability and fault tolerance in highly distributed environments that ClickHouse achieves through its complex use of Keeper for distributed operations coordination and eventual consistency.
User implications
In ClickHouse, the possibility of dirty reads - where users can write data to one replica and then read potentially unreplicated data from another—arises from its eventually consistent replication model managed via Keeper. This model emphasizes performance and scalability across distributed systems, allowing replicas to operate independently and sync asynchronously. As a result, newly inserted data might not be immediately visible across all replicas, depending on the replication lag and the time it takes for changes to propagate through the system.
Conversely, PostgreSQL's streaming replication model typically can prevent dirty reads by employing synchronous replication options where the primary waits for at least one replica to confirm the receipt of data before committing transactions. This ensures that once a transaction is committed, a guarantee exists that the data is available in another replica. In the event of primary failure, the replica will ensure queries see the committed data, thereby maintaining a stricter level of consistency.
Recommendations
Users new to ClickHouse should be aware of these differences, which will manifest themselves in replicated environments. Typically, eventual consistency is sufficient in analytics over billions, if not trillions, of data points - where metrics are either more stable or estimation is sufficient as new data is continuously being inserted at high rates.
Several options exist for increasing the consistency of reads should this be required. Both examples require either increased complexity or overhead - reducing query performance and making it more challenging to scale ClickHouse. We advise these approaches only if absolutely required.
Consistent routing
To overcome some of the limitations of eventual consistency, users can ensure clients are routed to the same replicas. This is useful in cases where multiple users are querying ClickHouse and results should be deterministic across requests. While results may differ, as new data inserted, the same replicas should be queried ensuring a consistent view.
This can be achieved through several approaches depending on your architecture and whether you are using ClickHouse OSS or ClickHouse Cloud.
ClickHouse Cloud
ClickHouse Cloud uses a single copy of data backed in S3 with multiple compute replicas. The data is available to each replica node which has a local SSD cache. To ensure consistent results, users therefore need to only ensure consistent routing to the same node.
Communication to the nodes of a ClickHouse Cloud service occurs through a proxy. HTTP and Native protocol connections will be routed to the same node for the period on which they are held open. In the case of HTTP 1.1 connections from most clients, this depends on the Keep-Alive window. This can be configured on most clients e.g. Node Js. This also requires a server side configuration, which will be higher than the client and is set to 10s in ClickHouse Cloud.
To ensure consistent routing across connections e.g. if using a connection pool or if connections expire, users can either ensure the same connection is used (easier for native) or request the exposure of sticky endpoints. This provides a set of endpoints for each node in the cluster, thus allowing clients to ensure queries are deterministically routed.
Contact support for access to sticky endpoints.
ClickHouse OSS
To achieve this behavior in OSS depends on your shard and replica topology and if you are using a Distributed table for querying.
When you have only one shard and replicas (common since ClickHouse vertically scales), users select the node at the client layer and query a replica directly, ensuring this is deterministically selected.
While topologies with multiple shards and replicas are possible without a distributed table, these advanced deployments typically have their own routing infrastructure. We therefore assume deployments with more than one shard are using a Distributed table (distributed tables can be used with single shard deployments but are usually unnecessary).
In this case, users should ensure consistent node routing is performed based on a property e.g. session_id or user_id. The settings prefer_localhost_replica=0, load_balancing=in_order should be set in the query. This will ensure any local replicas of shards are preferred, with replicas preferred as listed in the configuration otherwise - provided they have the same number of errors - failover will occur with random selection if errors are higher. load_balancing=nearest_hostname can also be used as an alternative for this deterministic shard selection.
When creating a Distributed table, users will specify a cluster. This cluster definition, specified in config.xml, will list the shards (and their replicas) - thus allowing users to control the order in which they are used from each node. Using this, users can ensure selection is deterministic.
Sequential consistency
In exceptional cases, users may need sequential consistency.
Sequential consistency in databases is where the operations on a database appear to be executed in some sequential order, and this order is consistent across all processes interacting with the database. This means that every operation appears to take effect instantaneously between its invocation and completion, and there is a single, agreed-upon order in which all operations are observed by any process.
From a user's perspective this typically manifests itself as the need to write data into ClickHouse and when reading data, to guarantee that the latest inserted rows are returned. This can be achieved in several ways (in order of preference):
- Read/Write to the same node - If you are using native protocol, or a session to do your write/read via HTTP, you should then be connected to the same replica: in this scenario you're reading directly from the node where you're writing, then your read will always be consistent.
- Sync replicas manually - If you write to one replica and read from another, you can use issue
SYSTEM SYNC REPLICA LIGHTWEIGHTprior to reading. - Enable sequential consistency - via the query setting
select_sequential_consistency = 1. In OSS, the settinginsert_quorum = 'auto'must also be specified.
See here for further details on enabling these settings.
Use of sequential consistency will place a greater load on ClickHouse Keeper. The result can mean slower inserts and reads. SharedMergeTree, used in ClickHouse Cloud as the main table engine, sequential consistency incurs less overhead and will scale better. OSS users should use this approach cautiously and measure Keeper load.
Transactional (ACID) support
Users migrating from PostgreSQL may be used to its robust support for ACID (Atomicity, Consistency, Isolation, Durability) properties, making it a reliable choice for transactional databases. Atomicity in PostgreSQL ensures that each transaction is treated as a single unit, which either completely succeeds or is entirely rolled back, preventing partial updates. Consistency is maintained by enforcing constraints, triggers, and rules that guarantee that all database transactions lead to a valid state. Isolation levels, from Read Committed to Serializable, are supported in PostgreSQL, allowing fine-tuned control over the visibility of changes made by concurrent transactions. Lastly, Durability is achieved through write-ahead logging (WAL), ensuring that once a transaction is committed, it remains so even in the event of a system failure.
These properties are common for OLTP databases that act as a source of truth.
While powerful, this comes with inherent limitations and makes PB scales challenging. ClickHouse compromises on these properties in order to provide fast analytical queries at scale while sustaining high write throughput.
ClickHouse provides ACID properties under limited configurations - most simply when using a non-replicated instance of the MergeTree table engine with one partition. Users should not expect these properties outside of these cases and ensure these are not a requirement.
Replicating or migrating Postgres data with ClickPipes (powered by PeerDB)
PeerDB is now available natively in ClickHouse Cloud - Blazing-fast Postgres to ClickHouse CDC with our new ClickPipe connector - now in Private Preview. Please sign up here
PeerDB enables you to seamlessly replicate data from Postgres to ClickHouse. You can use this tool for
- continuous replication using CDC, allowing Postgres and ClickHouse to coexist—Postgres for OLTP and ClickHouse for OLAP; and
- migrating from Postgres to ClickHouse.